Search Engines
Index & Reverse Index
yash101
Published 2/7/2025
Updated 2/7/2025
Jump to Page 📚
🔄 Where we left off
In the previous page, we implemented data acquisition and data cleanup. We are now able to:
- Acquire some text data (enron emails)
- Clean up the text
- Tokenize the text into lists of tokens
💡 Indices
In the first part of this series, Introduction to the Search Problem, we did a thought experiment into using the table of contents and the index of a textbook to find more about a topic. Can we use the same methods to search our corpus?
- Corpus
- In search, a corpus is simply the collection of text documents that a search engine indexes and retrieves results
🤔 Think to yourself, how do you find a topic in a textbook?
🗃️ Building an Index
🤔 Think to yourself, How are table of contents and indices created in books?
Textbooks are written manually by authors and edited by a team of editors. The amount of text and the number of concepts and terms in a textbook are finite. Thus, editors have the ability to pick and choose which topics and terms will be the most useful for their readers.
However, if you are building a replacement to Google, it is impossible to manually extract the important topics to build an index from each page of each website.
🤔 Think to yourself, what information is required to build an index? And how can we build an index programmatically?
🧩 The Morphology of an Index
The index in a textbook maps each entry to the pages which contain it. Example index entry:
A
Antibiotics, 65-68
Archaea, 15, 22-24
Autotrophic bacteria, 30
D
DNA replication in prokaryotes, 32-34
H
Horizontal gene transfer, 38-42
M
Microbiome, 60-63
Mitochondria (Endosymbiotic Theory), 70
P
Pathogenic bacteria, 55-58
Plasmids, 36
Prokaryotic ribosomes, 21
R
Ribosomes, 21
Respiration in prokaryotes, 44
V
Viruses vs. Bacteria, 75-78
Notice when looking for prokaryote, how our index has the following entries:
- DNA replication in prokaryotes
- Prokaryotic ribosimes
- Respiration in Prokaryotes
Each entry in the index contains a list of pages where to look to read more.
🤨 Terminology: Index, Forward Index, Reverse Index, Inverted Index
There are two ways we can represent our documents, each of which has its own purpose: the “forward index” and “reverse index” (also known as an inverted index, or index).
Let’s illustrate a simple example:
Documents
---------
1️⃣ The cat sits on the mat.
2️⃣ The dog sleeps on the mat.
3️⃣ The cat and dog play together.
4️⃣ The quick brown fox jumps over the lazy dog
A forward index contains the list of tokens in each document:
Forward Index
-------------
1️⃣ { The, cat, sits, on, the, mat }
2️⃣ { The, dog, sleeps, on, the, mat }
3️⃣ { The, cat, and, dog, play, together }
4️⃣ { The, quick, brown, fox, jumps, over, the, lazy, dog }
The reverse index contains the list of documents which contain each token.
Reverse index
-------------
the: 1️⃣2️⃣3️⃣4️⃣
cat: 1️⃣3️⃣
sits: 1️⃣
on: 1️⃣2️⃣
mat: 1️⃣2️⃣
dog: 2️⃣3️⃣4️⃣
sleeps: 2️⃣
and: 3️⃣
play: 3️⃣
together: 3️⃣
quick: 4️⃣
brown: 4️⃣
fox: 4️⃣
over: 4️⃣
lazy: 4️⃣
If we want to search “dog cat play”, we can look up in the index:
dog: 2️⃣3️⃣4️⃣
cat: 1️⃣3️⃣
play: 3️⃣
And let’s simply rank the documents on which was found most:
3️⃣: 3 hits
2️⃣: 1 hit
1️⃣: 1 hit
4️⃣: 1 hit
Thus, the best result for our query is document 3️⃣.
- Forward Index
- a data structure which maps each document to tokens it contains.
- Reverse index, Inverted index, Index
- a mapping from a token to its appearances
- in search engines, we can use a reverse index to map a token to the documents it appears in
🧑💻 Coding a Reverse Index
Let’s attempt to code this!
☕️ The code!
class Indexer {
constructor() {
this.idx = new Map();
}
index(text, uri) {
// Build a forward index from the document
const tokens = new Set();
tokenize(preprocess(text)).forEach(wordSet.add);
// Update the reverse index with all of our tokens
for (const token of tokens) {
if (!this.idx.has(token)) {
this.idx.set(token, []);
}
this.idx.get(token).push(uri);
}
}
}
⚙️ How does it work?
- Since a reverse index maps a term to its occurrences, we will use a JavaScript
Mapobject to hold the reverse indexthis.idx = new Map()creates the Map which we will use
- We tokenize the text and generate a list of tokens
tokenize(preprocess(text))string[]
- We add each token to a JavaScript
Setto deduplicateconst tokens = new Set();creates a set to add tokens to(...).forEach(wordSet.add)adds each token to that set
- We add each token to the index:
for (const token of tokens) { ... } - For each token, we check if it exists in the reverse index. If it doesn’t, then we add an empty array to the index
if (!this.idx.has(token)) {
this.idx.set(token, []);
}
- We add the document identifier for the array in the reverse index for each token
this.idx.get(token).push(uri);
Indexing our Corpus (Enron emails dataset) 📚
Now that we know how to index our corpus and have built our index(document) function, we just need to feed in documents to build an index.
const indexer = new Indexer();
// ...
for await (const [ filepath, contents ] of readFilesRecursively(dirPath)) {
try {
indexer.index(contents, filepath);
} catch (e) {
console.log(filepath, contents);
console.error(e);
}
}
I ran this function and indexed the entire Enron emails dataset.
Searching Using a Reverse Index 🕵️♀️
Building the reverse index is the hard part. Turns out that searching with a reverse index is easy and very efficient.
The time complexity of the search operation, where
And the space complexity of the search operation, where
Pseudocode Steps to search using a reverse index:
- Normalize the search query to the reverse index. This is fancy speak for use the exact same methods to process the search query as the contents of the reverse index.
- Create a hash map to map each document found to the number times it was found.
- Add a document to the hash map if it is a hit and increment its hit count (score)
- Rank the documents based on these scores
Implemented,
query(searchQuery) {
if (!searchQuery)
return [];
// List of tokens in the search query
const tokens = new Set(tokenize(preprocess(searchQuery)));
// Forward index we will build by reversing the reverse index
const unrankedResults = new Map();
for (const token of tokens) {
// Get all documents associated with a token
const hits = idx.get(term) || [];
// Add each document to the unrankedResults map and/or increment their value (+1 for each time a document is found)
for (const hit of hits) {
const current = unrankedResults.get(hit) || 0;
unrankedResults.set(hit, current + 1);
}
}
return Array
.from(unrankedResults.entries())
.sort((a, b) => b[1] - a[1])
}
Try the Demo Below: it implements searching with a prebuilt reverse index of 5 documents.
Further Learning:
- Try playing with the search functionality above. Try adding or modifying
doSearch(query)to try more queries. - Try understanding how the reverse index works (format the JSON for the index and understand how it works)
🐘 The Elephant in the Room
The index in the playground is humongous. And to make matters worse, it was built with just 5 documents! Our naïve reverse index does not scale well!
Attempting to index the entire Enron email dataset resulted in a disastrously big index. The memory usage of Node.js was 2 GB of RAM, quite a costly VPS or pod!
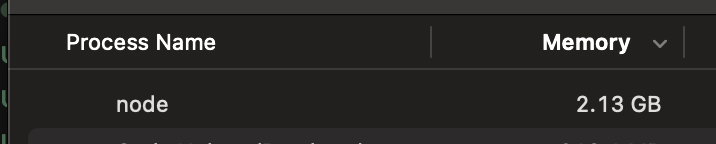
Next, I tried dumping the full index, only to get an error that the JSON blob was too big to write. Oh, and yes, that is
debug
1080813
file:///Users/yash/code/microsearch/runner.js:84
fs.writeFile('debug.json', JSON.stringify(Object.fromEntries(index.idx), null, 2));
^
RangeError: Invalid string length
at JSON.stringify (<anonymous>)
at file:///Users/yash/code/microsearch/runner.js:84:39
at process.processTicksAndRejections (node:internal/process/task_queues:105:5)
Node.js v22.13.0
Our goal was to be able to do fullly client-side search on a large dataset. Unfortunately, that is currently sounding like a pipe dream!
🎒 Summary
In this article, we learned what a forward index and reverse index are in a search engine. We also used our intuition on how to find a word in a textbook to develop the data structures and algorithms required to create the forward and reverse index.
⏭️ Next Section
The next section is a workshop where you will build a search engine using a reverse index and train it on Æsop’s Fables.